AI 와 함께 코딩하기
뻔히 보이는 코드 그냥 바꾸어도 되는데, 혹시 싶어 LLM 에다 던져본다.
Window Copilot, 뤼튼, Perplexity, ChaGPT, Cloude...
유료모델을 안써서 그런지, LLM이 요구를 넘어선 코드까지 만들어 준다.
핵심 알고리즘만 만들어 주면 되는데 ...
요청사항을 자세히 안써서 그런가?
열심히 구체적으로 써본다.
프롬프트가 많이 길어진다.
그런데, 세부항목은 논리충돌이 조금 있는 것들.
내가 보기에도 뭔 말인가 싶다.
에라 모르겠다.
정리하기 귀찮지만, 원하는 건 맞으니 요청함.
그런데 LLM이 그걸 무시하고 자기가 해석한대로 코드를 뱉아낸다.
아이 참. 프롬프트를 하루종일 바꾸어봐도 이 할루시네이션이 극복이 안된다.
조금 실수를 하니, LLM별로 다른 설계를 뱉어낸다.
그런데 각 방법이 달라서 중간쯤 선택장애가 왔다.
아, 짜증... 계산기 하나 만드는 게 이렇게 어렵나?
AI의 인격

- Copilot 에게 바보같이 질문을 해본다.
- Copilot이 질문의 테두리 내에서 해결책을 찾으려고 엄청 복잡한 코드를 리턴한다.
- 나는 그 코드가 잘못 되었는지 모르고 복붙해본다.
- 에러는 발생하지 않는데, 앱이 계속 원하는대로 동작하지 않는다.
화면을 보면서 멍하니 고민을 좀 하다가 "이렇게 해보면 어떨까?"라는 생각이 들었다.
- 나름대로 그럴싸한 논리 흐름을 먼저 구상했다. (코드만 모를 뿐 논리는 창작을 했다.)
- 처리하고 싶은대로 '프롬프팅'을 만들었다. (몇번을 고쳐썼는지 모른다.)
- 그랬더니 Copilot 이 코드도 간결하게 꽤 그럴싸하게 답변을 해준다.
- 필요한 부분을 붙여넣고 손을 좀 보니 앱이 원하는대로 동작한다.
Perplexity 나 cloude, ChatGPT도 마찬가지.
횡설수설하는 걸 막고 주제에 집중하기 위해 이렇게 만든 것 같다.
딱 묻는 말에만 대답을 잘 해주는 인격을 만들어놓은 듯.
땅바닥에서 시작해 달나라까지 가면서 횡설수설할 수 있을 거 같은데,
그건 극도로 제한 놓은 모양이다.
어디까지를 '제대로 된 대답'인지 규정할 수 없기 때문 아닐까.
일단, 이 상황을 그대로 받아들인다면 !
부족한 정보

Copilot이나 ChatGPT는 "대화"를 주제로 만들어졌다.
그래서 대화를 통해 얻을 수 있는 단편적 지식은 꽤 괜찮은 것 같다.
부끄러워서 묻지 못했거나,
답변자가 귀찮을까봐 많이 묻지 못했던 걸 LLM으로 해결할 수 있을 것 같다.
하지만, 지식의 한 세트, Specification 문서를 통째로 얻을 순 없었다.
그래서 RAG가 나온거겠지.
답변을 신뢰하기 위해서는 출처가 필요하고 출처의 신뢰도도 필요한데, 이 연계는 아직 연구가 모자란 것 같다.
답변을 신뢰하는 행위까지 가는 건 시간이 좀 더 필요할 듯.
신뢰의 심리학적 메커니즘도 아직 완벽히 밝혀진 건 아니니까.
AI를 어떻게 활용할 것인가?
AI를 잘 쓰기 위해서는 결국 사람이 똑똑해져야 한다는 말이다.
그런데, 어떻게 해야 똑똑해지지?
AI가 말친구가 되어줄테니 지적성장은 눈에 띄게 빨라지겠지만,
어떤 사람으로 성장할거냐 하는 건 시간이 좀 걸릴 듯.
사람들이 생각하고 판단하고 결정해야 하니까.
그래야 그게 교육으로도 갈테니.
나야 알아서 쓴다고 하지만, 이제 지식 세계에 입문하는 사람들 입장에선 곤욕스러울 듯.
코딩할 때 ChatGPT를 쓰는 초보자들이, 헤매는 경우가 많다는 연구를 보고 생각이 많아졌다.
AI가 문제가 아니라, 사람이 모르는 것.
사람이 몰라서 AI의 답변을 잘 적용할 수 없었던 것.
초보자에게 일어나는 이 모습이, 베테랑에게도 일어난다.
단지 작아서 눈에 띄지 않을 뿐.
기타 등등.
앞으로 우리 사회가 AI와 함께 어떻게 변해갈지 궁금해진다.
※ Update : 2024.09.23
이 글을 올리고 나니, 오픈AI가 o1을 출시했다고 한다. (2024.9.12)
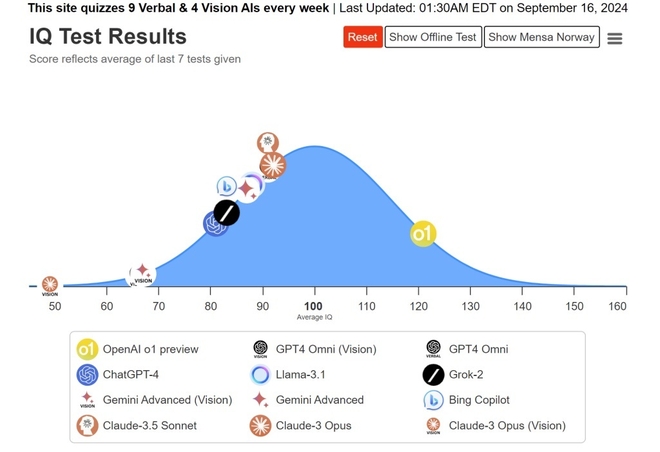
"AI트래킹"이라는 곳에서 "노르웨이 멘사 테스트"를 시켜봤더니 IQ 120이 나왔다고 한다.
중요한 건 그 이전의 AI들은 80~90 이라는 거.
이에 내가 위에서 느꼈던 부족함의 정체 같다.
국제수학올림피아드 문제를 풀게 했더니, 정답률은 13%였다고 한다.
o1 이 나오고서야 83% 가 되었다고.
아, 정말. 당장 개발자 다 대체될 것처럼 말하더니 다 거짓말이었던 거다.
물론 지금 수준도 대단한 건 맞다. 확실히 코딩에 도움이 된다.
하지만, 호들갑을 떨던 건 다 거짓말이었던 것.
유튜브는 과장이 기본이라는 걸 잊었다.
유튜브로 세상을 판단하면 안되겠다.
결론.
1) 찍먹하지 말고 진지하게 개발해보자.
2) 내가 경험하지 않은 건 그냥 들은 이야기일 뿐이다.
끝.
'프로젝트 > 개발일지' 카테고리의 다른 글
| Flutter : 나를 괴롭혔던 SDK Version 불일치 (7) | 2024.11.06 |
|---|---|
| Flutter로 앱개발 시작하기 (11) | 2024.11.01 |
| 한달 동안 AI와 함께 Flutter앱을 개발하면서 느낀 점 (2) | 2024.08.29 |
| MySQL Error 1206, 데이터 엔지니어의 눈으로 바라보기 (0) | 2020.07.20 |
| cron 작업 걸기, log 파일 0 byte 문제 (0) | 2020.03.04 |




댓글